How to Scrape Twitter (X) Trends Without Breaking the Bank
How to Scrape Twitter (X) Trends Without Breaking the Bank
If you want to know what the world is thinking right now, you look at Twitter (X). With over 500 million tweets sent every single day, Twitter (X) is the undisputed pulse of the internet. It is described as the place where news breaks, memes go viral, and public opinion shifts in real-time. In fact, nearly half of all US social media users rely on X specifically to get their latest news. For marketers, researchers, and developers, this real-time data is a goldmine, but lately, it’s been buried behind an incredibly expensive paywall.
Since the platform's overhaul, the days of easy, free API access are gone. Official enterprise tiers now command prices that start at a staggering $42,000 a month. Practically overnight, individual developers and small teams were priced out of the conversation. And if you’ve tried building your own "DIY" scraper lately, you know it’s a constant battle against IP bans and fragile selectors that break every time the site updates its layout.
If you’re done fighting with broken scripts or staring at impossible API invoices, this article will guide you towards scraping Twitter (X) trends without breaking the bank. We’re going to explore how you can scrape Twitter Trend data reliably and affordably in 2026 and beyond using the Twitter (X) Trends Scraper on Apify.
The "Now" Economy: Why You Can't Afford to Ignore Twitter Trends
Before we dive into the how, let's talk about the why. Why are brands, hedge funds, and news agencies so obsessed with "Trending Topics"?
Because social media moves so fast that if you blink, you're already behind. We’re currently living in a world where the rules are being rewritten every few weeks. AI influencers with millions of followers are the new norm, raw audio-first spaces are replacing video curation, and one-click social shopping has fundamentally changed how we spend money.
The old ways of measuring success are dying, too. We're seeing a pivot away from "likes" toward meaningful shares and saves, while the rise of "finstas" (fake Instagram accounts) shows just how much people are craving raw, unfiltered connection over curated perfection. In this type of landscape marked by ephemeral content and overtly personalized niche communities, you either have real-time data or you’re invisible.
This is why X (Twitter) is the global town square. While other platforms are for highlights and professional posturing, X is where news breaks, memes are born, and brand reputations are either made or broken in real-time. If you aren't tracking the pulse of X, you're trying to navigate the digital landscape with a map from ten years ago, ultimately making you obsolete.
Why Scrape Twitter?
Monitoring trends isn't just about watching hashtags. Monitoring trends is also about decoding the world’s most active conversation in real-time. Here is how businesses, researchers, and creators are turning raw X data into a competitive advantage:
Master the Art of "Newsjacking"
Newsjacking is the skill of injecting your brand into a breaking story at the perfect moment. Think back to Oreo’s "You can still dunk in the dark" tweet during a Super Bowl blackout. That tweet wasn't luck; it was real-time awareness. To pull this off, you need to know what is trending the moment it happens. Speed is the only metric that matters here.
Hyper-Local Market Intelligence
Global trends are interesting, but local trends are profitable. If you’re a retailer, knowing that #WinterCoats is trending in New York while #BeachVibes is dominant in Sydney allows for precision targeting. No matter where you are, whether in Lagos, London, or Los Angeles, having access to granular location data ensures your message hits the right people at the right time.
Unmasking Customer Behavior & Sentiment
What are people actually feeling? By scraping interactions and performing sentiment analysis, you can move past raw numbers to understand customer pain points and expectations. This emotional intelligence helps you tailor your products and services to what your audience actually wants, rather than what you think they want.
Competitive Intelligence on Autopilot
Monitoring your competitors’ activities reveals their marketing playbook in real-time. From spotting their latest product launches to seeing how their customers are reacting to a new policy, this data provides you with the tactical insights you need to stay one step ahead.
A Goldmine for Social & Academic Research
For researchers studying everything from political movements to public health trends, X is the ultimate dataset. Automated scraping provides the scale and historical context needed to uncover patterns, track the spread of information, and gauge public opinion on a global scale, all backed by hard data.
Content Inspiration on Tap
Writer's block is a productivity killer. By examining trending "tag clouds" and emerging discussions, content creators can instantly see what topics are currently resonating. This ensures your next post or video rides an existing wave of interest rather than struggling for attention in a vacuum.
The Problem: The Great Data Wall of X
The business case for this data is ironclad, but the reality is that actually accessing it has become a significant challenge.
The Death of the Free API
For a decade, the Twitter API was the playground of the internet. You could write a Python script in 10 minutes and stream tweets. Today, those gates are locked tight.
X has replaced the once-open ecosystem with a tiered pricing structure that makes data access either trivial or prohibitively expensive:
- Free ($0/mo): Strictly for testing and bots that post content. You get a measly 100 posts/month in reads. That’s barely enough to refresh a single feed once.
- Basic ($200/mo): Aimed at hobbyists and prototypes. It bumps you up to 15,000 reads per month, which disappears in a flash if you’re trying to track shifting trends across different regions.
- Pro ($5,000/mo): This is where you get 1 million reads and full-archive search. It’s for scaling businesses, but the price tag is a massive barrier for most developers and small teams.
- Enterprise: For anything larger, you’re looking at custom solutions. With enterprise pricing rumored to start at $42,000 a month, it’s clear that a "Pay-to-Play" reality has replaced the "Golden Age" of data access.
If you’re an indie developer or a small marketing team, these invoices aren't just an expense; they're definitely a death sentence for your project.
The "DIY Scraper" Trap
"Fine," you think, "I'll just whip up a Python script with Selenium or Playwright and do it myself."
Before you start writing that first line of code, you need to understand the technical gauntlet X has thrown down. Modern Twitter isn't just a website; it’s a system designed to keep automated traffic out. Here is why your "quick weekend project" will likely turn into a full-time maintenance nightmare:
- Obfuscated and Dynamic DOM: X doesn't use semantic classes like
trend-item. Instead, they use auto-generated, randomized strings such ascss-175oi2r r-18u37iz. These can change during a deployment or even based on your session. Your selectors will break frequently, requiring you to rewrite your parsing logic every week. - Aggressive Fingerprinting: It’s not just about your IP address anymore. X analyzes your browser fingerprint, Canvas rendering, WebGL info, and even how you handle headers. If your headless browser looks like a bot, you’ll be met with a "Something went wrong" screen or a permanent block before you even fetch the trends.
- The Resource Drain of SPAs: X is a heavy Single Page Application (SPA). To scrape it, you must run a full headless browser to execute JavaScript and handle infinite scrolling. This consumes massive amounts of CPU and RAM, especially when scaling. What starts "free" on your laptop quickly becomes a triple-digit server bill.
- Evolving Bot Detection: Between Cloudflare protection and internal behavioral analysis, X is constantly looking for patterns. If you don't vary your mouse movements, scroll speeds, and request intervals perfectly, your scraper will be flagged and throttled into oblivion.
Suddenly, that "free" DIY project is costing you 20+ hours a week in troubleshooting to keep the data flowing.
The Solution: The Twitter (X) Trends Scraper on Apify
Enter the Twitter (X) Trends Scraper. This isn't just another script; it's a production-grade Actor hosted on the Apify platform. It serves as a bridge between the chaos of the open web and the structured data needs of your business. It bypasses the complexity of the official API and the fragility of DIY scrapers.
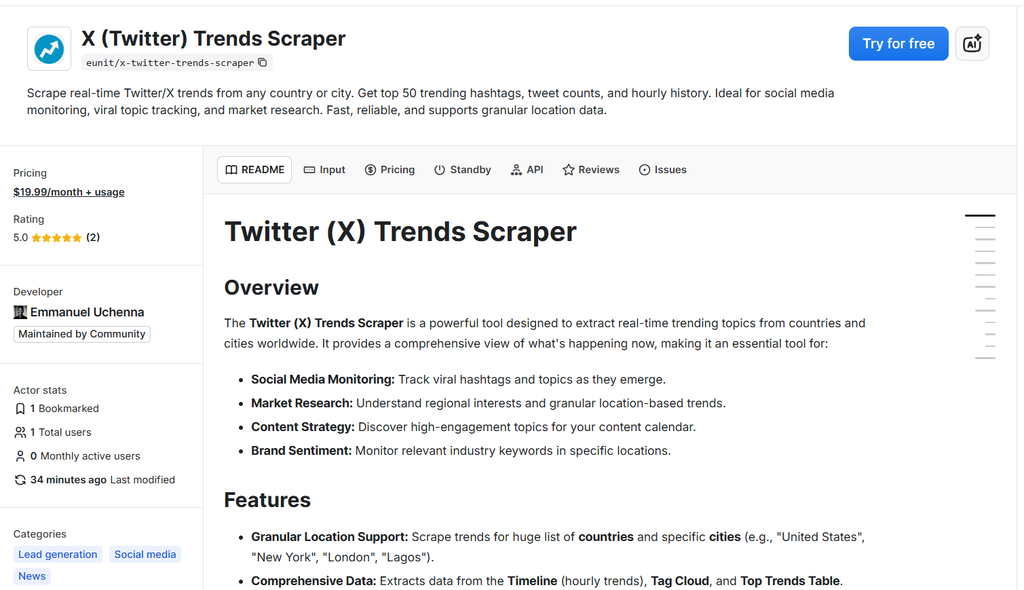
X (Twitter) Trends Scraper
Here is why it’s the superior choice for 2026 and beyond.
1. Granular Location Targeting (The Secret Sauce)
Most generic scrapers only provide options for "Worldwide" or "USA". This Actor goes deeper. Much deeper. It leverages Twitter (X) data to allow you to select specific Cities and Countries.
- Want to know what's buzzing in Kano, Nigeria? You can.
- Need to compare trends in Birmingham, UK vs Birmingham, Alabama? Done. This level of detail is critical for localized marketing campaigns and sociological research.
2. No Proxies? No Problem
If you were running a scraper locally, you'd need to buy a pool of Rotating Residential Proxies to avoid getting blocked. These can cost hundreds of dollars a month. The Twitter Trend Scraper handles all of this infrastructure for you. When you run the Actor on Apify, it utilizes their vast pool of IP addresses. You don't need to configure anything; you click "Run".
3. Pay-Per-Event Pricing (The Fair Model)
Subscription models are annoying. Why pay 99 USD per month if you only need to scrape data once a week? The Twitter Trend Scraper operates on a Pay-Per-Event model. You are charged a tiny fee only when you successfully scrape a scraping run. If you run it 10 times, you pay for 10 runs. If you don't use it for a month, you pay $0. It scales perfectly with your needs, from a hobbyist project to an enterprise dashboard.
4. Rich, Structured Data Output
It doesn't just give you a list of hashtags. You get a comprehensive JSON dataset including:
- Rank: Is it #1 or #49?
- Name: The hashtag or keyword.
- Tweet Volume: "10K Tweets" vs "2M Tweets".
- Context: The direct link to the search page.
- History: Hourly timeline data.
Example Output from the Actor
[ { "scraped_at": "2025-12-31T19:00:09.948042", "country_input": "Worldwide", "timeline": [ { "datetime": "Wed Dec 31 2025 18:08:19 GMT+0000 (Coordinated Universal Time)", "timestamp": "1767204499.747", "trends": [ { "rank": 1, "name": "Happy New Year", "link": "https://twitter.com/search?q=Happy%20New%20Year", "tweet_count": "2141151" }, { "rank": 2, "name": "#CDTVライブライブ", "link": "https://twitter.com/search?q=%23CDTV%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%82%A4%E3%83%96", "tweet_count": "269605" }, // ... ] }, { "datetime": "Wed Dec 31 2025 17:16:15 GMT+0000 (Coordinated Universal Time)", "timestamp": "1767201375.892", "trends": [ { "rank": 1, "name": "Happy New Year", "link": "https://twitter.com/search?q=Happy%20New%20Year", "tweet_count": "1708901" }, { "rank": 2, "name": "新年早々", "link": "https://twitter.com/search?q=%E6%96%B0%E5%B9%B4%E6%97%A9%E3%80%85", "tweet_count": "80971" }, // ... ] }, { "datetime": "Wed Dec 31 2025 16:24:31 GMT+0000 (Coordinated Universal Time)", "timestamp": "1767198271.186", "trends": [ { "rank": 1, "name": "Happy New Year", "link": "https://twitter.com/search?q=Happy%20New%20Year", "tweet_count": "1270217" }, { "rank": 2, "name": "#STARTOtoMOVE生配信", "link": "https://twitter.com/search?q=%23STARTOtoMOVE%E7%94%9F%E9%85%8D%E4%BF%A1", "tweet_count": "282088" }, // ... ] }, { "datetime": "Wed Dec 31 2025 16:24:18 GMT+0000 (Coordinated Universal Time)", "timestamp": "1767198258.898", "trends": [ { "rank": 1, "name": "Happy New Year", "link": "https://twitter.com/search?q=Happy%20New%20Year", "tweet_count": "1270217" }, { "rank": 2, "name": "#STARTOtoMOVE生配信", "link": "https://twitter.com/search?q=%23STARTOtoMOVE%E7%94%9F%E9%85%8D%E4%BF%A1", "tweet_count": "282088" }, // ... ] }, // ... ], "tag_cloud": [], "table_data": [] } ]
How to Get Started (In Under 5 Minutes)
You don't need to be a coding wizard to use this Actor. Here is your Zero-to-Data walkthrough.
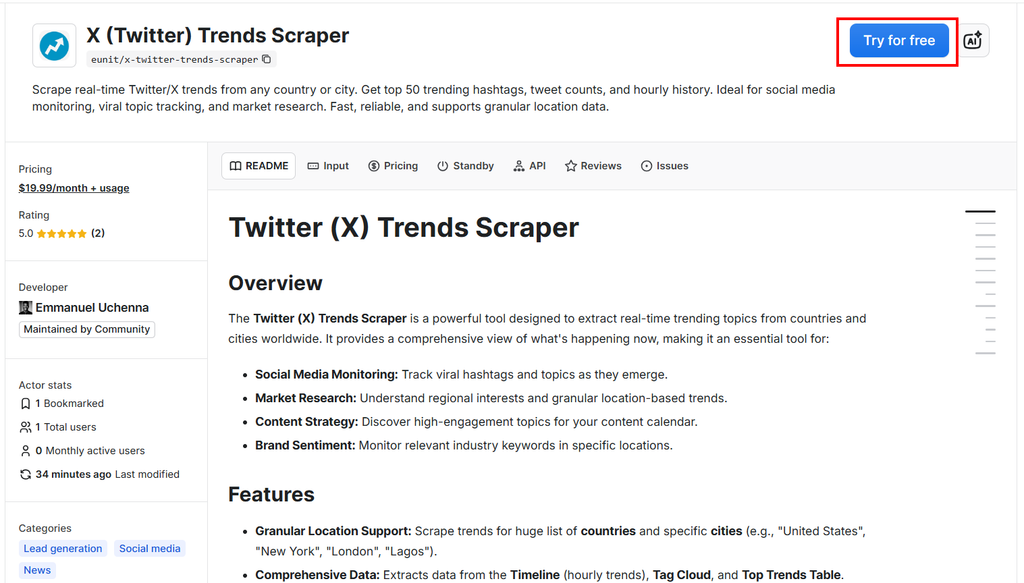
Step 1: Access the Actor
Head over to the Twitter (X) Trends Scraper page on Apify. Click the "Try for free" button to create your account.
Twitter (X) Trends Scraper page on Apify
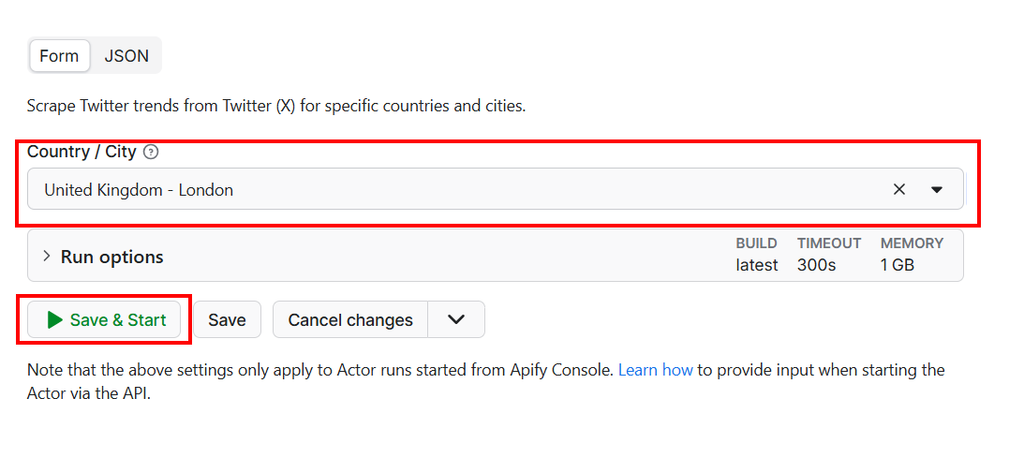
Step 2: Configure Your Input
You will see a user-friendly interface.
- Look for the Country dropdown.
- Select your target. Let's say...
United Kingdom - London. - (Optional) You can leave everything else as the default.
Step 3: Run & Export
Hit the green Save & Start button at the bottom. Boom. The Actor will spin up, navigate the web, extract the data, and shut down. In a few seconds, you will see your results in the Output tab. You can view them as a table or download them in JSON, CSV, Excel, or XML formats.
Twitter (X) Trends Scraper page on Apify
For the Developers: Automating the Pipeline
If you are a developer, you probably want to integrate this Actor into your own app. Maybe you're building a dashboard that alerts you when crypto coins start trending.
You can control this Actor programmatically using the Apify Client for Python (or Node.js).
from apify_client import ApifyClient # 1. Initialize the client client = ApifyClient("YOUR_API_TOKEN") # 2. Define your Input run_input = { "country": "united-states/new-york", } # 3. Call the Actor print("Fetching trends...") run = client.actor("eunit/x-twitter-trends-scraper").call(run_input=run_input) # 4. Fetch the results dataset_items = client.dataset(run["defaultDatasetId"]).iterate_items() for item in dataset_items: print(f"Stats for {item['country_input']}:") for trend in item['timeline'][0]['trends'][:5]: print(f"#{trend['rank']} {trend['name']} - {trend['tweet_count']}")
This snippet does in 10 lines what would take 500 lines of Selenium code to attempt (and fail) to do.
Is Scraping X Legal?
Ethical scraping is important. This actor scrapes publicly available factual data (trends). It does not scrape private profiles, log into accounts, or scrape personal data behind a login wall. Scraping public information is considered legal, but it is essential to review the Terms of Service of any site you interact with and ensure your usage complies with relevant regulations such as the GDPR.
Wrapping Up
Let’s be real: trying to keep up with Twitter (X) without automated data is like trying to catch a waterfall with a spoon. You might see a few drops, but the wave you need to ride has usually passed you by.
The $42,000-per-month "pay-to-play" era was intended to render social listening for everyone but the biggest corporations. But as we've seen, you don't need a massive enterprise budget to get enterprise-grade insights.
Stop wasting your time fighting with broken Selenium scripts or staring at invoices you can't justify. Focus on what you actually do best: analyzing the trends and making informed business decisions.
Try the Twitter (X) Trends Scraper today and start turning the chaos of social media into a clear signal for your success.

Emmanuel Uchenna
@eunit99Hi, I’m Emmanuel Uchenna — a frontend engineer, technical writer, and digital health advocate passionate about building technology that empowers people. With over five years of experience, I specialize in crafting clean, scalable user interfaces with React, Next.js, and modern web tooling, while also translating complex technical ideas into clear, engaging content through articles, documentation, and whitepapers.


